59 Unsupervised Prediction
59.1 Key Ideas
- Sometimes you don’t know the labels for prediction
- To build a predictor, you need to:
- Create clusters (Not a perfectly noiseless process)
- Name clusters (With EDA this can be challenging)
- Build predictor for clusters
- In a new data set
- Predict clusters
59.2 Irirs Example Ignoring Species Labels
# Load data and create training / testing sets
data(iris)
inTrain <- createDataPartition(y = iris$Species, p = 0.7, list = FALSE)
training <- iris[inTrain, ]
testing <- iris[-inTrain, ]
dim(training)## [1] 105 5## [1] 45 5# Cluster data using k-means clustering
kMeans1 <- kmeans(subset(training, select = -c(Species)), centers = 3)
# Add clustering data to training set
training$clusters <- as.factor(kMeans1$cluster)
# Visualise the result
ggplot(data = training, aes(x = Petal.Width, y = Petal.Length, col = clusters)) +
geom_point()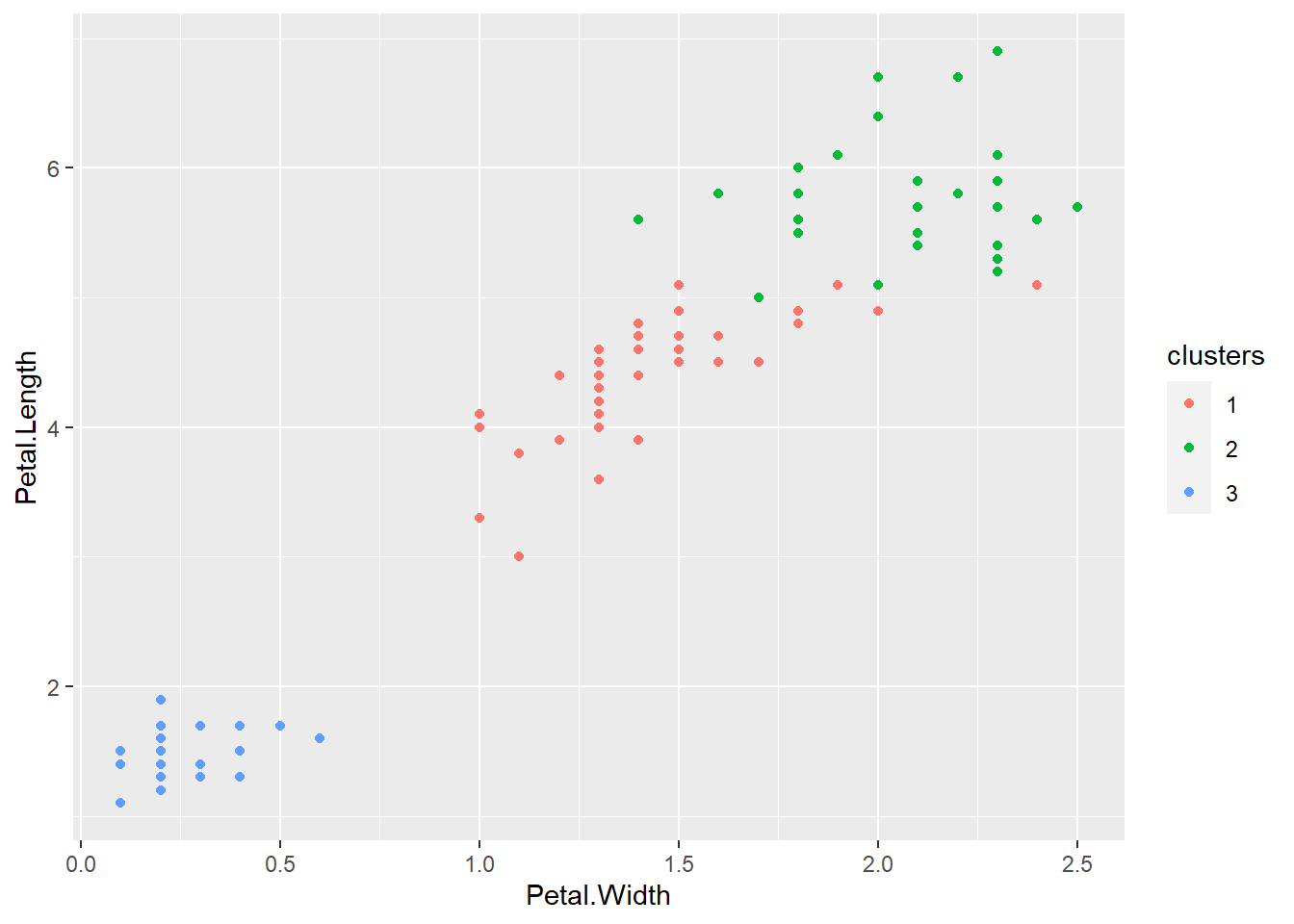
##
## setosa versicolor virginica
## 1 0 32 9
## 2 0 3 26
## 3 35 0 059.2.1 Build a Predictor
This model will relate the clusters that we have previously created to the variables of the training set using a tree algorithm. There is error and variation in the prediction building as well as error and variation in the cluster building.
modFit <- train(clusters ~., data = subset(training, select= -c(Species)), method = "rpart")
table(predict(modFit, training), training$Species)##
## setosa versicolor virginica
## 1 0 35 10
## 2 0 0 25
## 3 35 0 059.2.2 Apply on the Test Data Set
##
## testClusterPred setosa versicolor virginica
## 1 0 15 6
## 2 0 0 9
## 3 15 0 059.3 Notes
- The
cl_predict()function in thecluepackage provides similar functionality - Beware of over-interpretation of clusters
- This is one basic approach to recommendation engines
- Elements of statistical learning covers this, so does introduction to statistical learning