57 Combining Predictors (Ensembling Methods)
57.1 Key Ideas
- You can combine classifiers by averaging/voting
- Combining classifiers improves accuracy
- Combining classifiers reduces interpretability
- Boosting, bagging and random forests are variants of this theme
57.1.1 Basic Intuition - Majority Vote
Suppose we have 5 completely independent classifiers:
- If accuracy is 70% for each, \(10*(0.7)^3(0.3)^2+ 5(0.7)^4(0.3)^2+(0.7)^5\)
- 83.7% majority vote accuracy
With 101 independent classifiers: * 99.9% majority vote accuracy
57.2 Approaches for Combining Classifiers
- Bagging, boosting and random forests
- Usually combine similar classifiers
- Combining different classifiers
- Model stacking
- Model ensembling
57.3 Example with Wage Data
# Load data
data(Wage)
Wage <- subset(Wage, select=-c(logwage))
# Create a building data set and a validation set
inBuild <- createDataPartition(y = Wage$wage,
p = 0.7, list = FALSE)
validation <- Wage[-inBuild, ]
buildData <- Wage[inBuild, ]
inTrain <- createDataPartition(y = buildData$wage,
p = 0.7, list = FALSE)
training <- buildData[inTrain, ]
testing <- buildData[-inTrain, ]
# Check that worked
dim(training)## [1] 1474 10## [1] 628 10## [1] 898 10# Build Model
options(warn=-1)
mod1 <- train(wage ~., method = "glm", data = training)
mod2 <- train(wage ~., method = "rf", data = training, trControl = trainControl(method = "cv"), number = 3)
# Predict using the models
pred1 <- predict(mod1, testing)
pred2 <- predict(mod2, testing)
# Plot the models vs eachother
qplot(pred1, pred2, colour = wage, data = testing)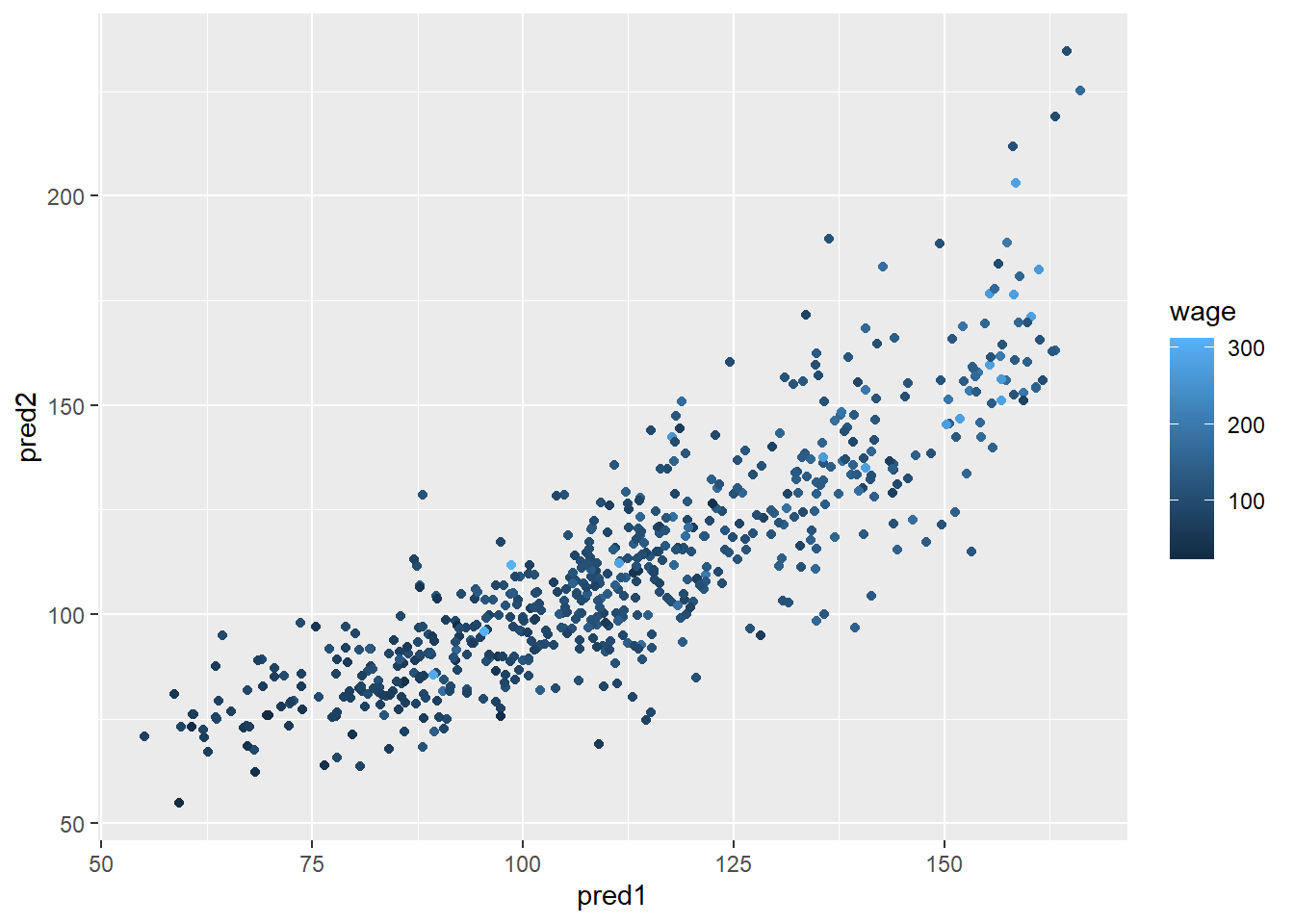
# Fit a model that combines the predictors
# Build new data set beased on the predictions of the other two models
predDF <- data.frame(pred1, pred2, wage = testing$wage)
combModFit <- train(wage ~., method = "gam", data = predDF)
combPred <- predict(combModFit, predDF)
# Testing Errors
sqrt(sum((pred1-testing$wage)^2))## [1] 869.6077## [1] 907.5452## [1] 856.3578# Predict on validation data set
pred1V <- predict(mod1, validation)
pred2V <- predict(mod2, validation)
predVDF <- data.frame(pred1=pred1V, pred2=pred2V)
combPredV <- predict(combModFit, predVDF)
# Evaluate on the validation set
sqrt(sum((pred1V-validation$wage)^2))## [1] 1005.59## [1] 1060.75## [1] 1006.35857.4 Notes
Blending models together can be really effective, even with simple models.
- Typical model for binary/ multiclass data
- Build an odd number of models
- Predict with each model
- Predict with calss by majority vote
- This can get dramatically more complicated
- Simple blending in caret:
caretEnsemble(use at your own risk)