37 In and out of sample error
In sample error: The error rate you get on the same data set you used to build your predictor. (Sometimes called resubsititution error)
Out of sample error: The error rate you get on a new dataset. (Sometimes called generalisation error)
Key Ideas:
- Out of sample error is what you care about.
- In sample error < out of sample error.
- The reason is overfitting, where you algorithm is matched to the data you have.
set.seed(1)
smallSpam <- spam[sample(dim(spam)[1], size=200),]
spamLabel <- (smallSpam$type == "spam")*1 + 1
# Average number of capital letters
plot((smallSpam$capitalAve), col=spamLabel, ylim = c(0,10))
abline(h=3)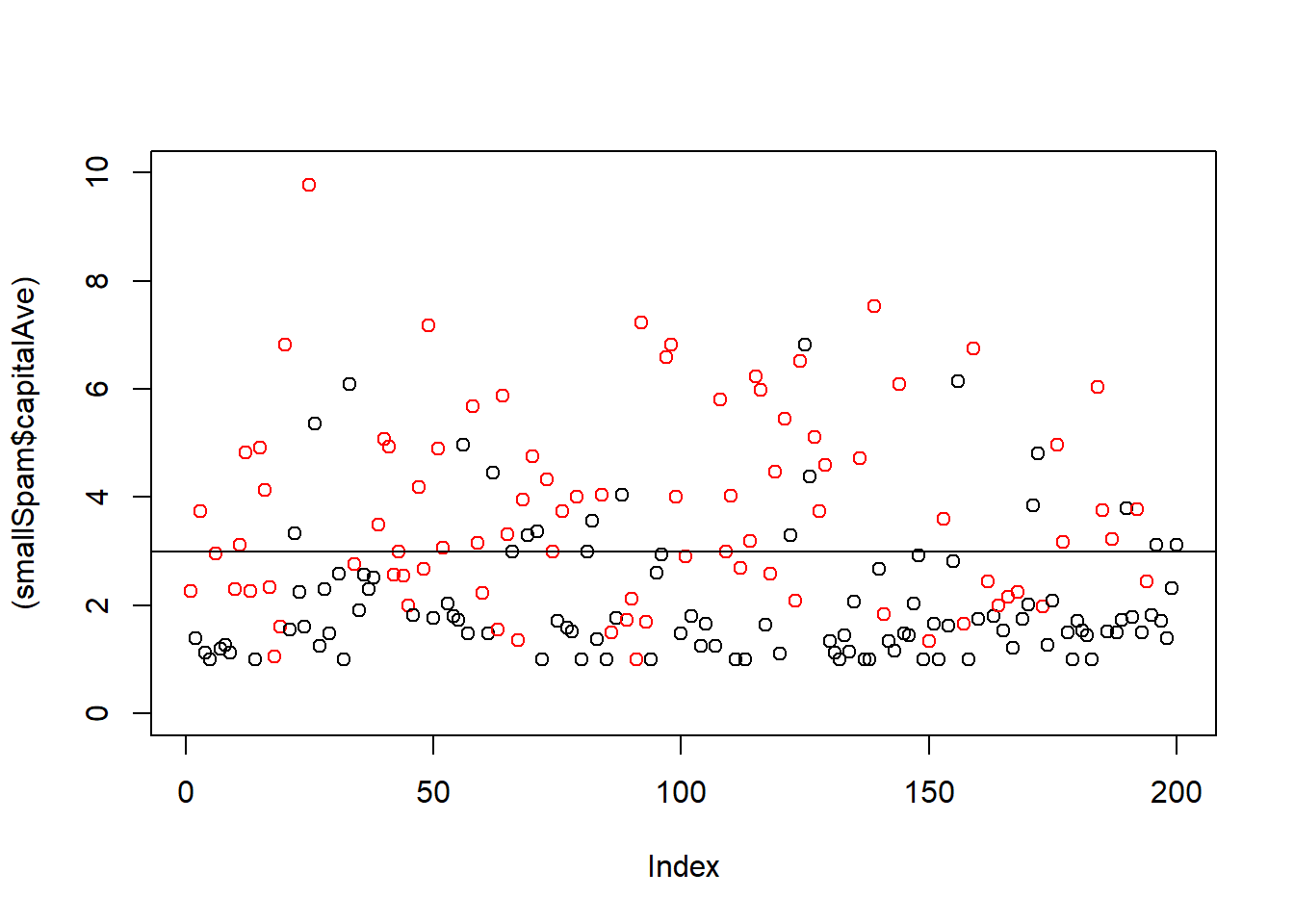
# Seems like spam mails have an average of more than 3 capital letters
rule1 <- function(x) {
prediction <- rep(NA, length(x))
prediction[x >= 2.6] <- "spam"
prediction[x < 2.6] <- "nonspam"
return(prediction)
}
table(rule1(smallSpam$capitalAve), smallSpam$type)##
## nonspam spam
## nonspam 85 28
## spam 26 6137.0.1 What’s going on?
Data have two components:
- Signal
- Noise
The goal of the predictor is to find the signal. You can always design a perfect in-sample predictor, however you capture both the signal and the noise when you do that. This means that this predictor will perform terribly on new samples.